
How We Discovered 18 Years of Hidden SaaS Pricing Data (And Why Competitors Can't Catch Up)
The untold story of how Archive.org became our secret weapon: 1,019 historical snapshots of 280 SaaS tools spanning 2007-2025. Why this 18-year data moat is worth more than any AI—and how long it will take competitors to replicate it.
The Discovery
1,019 historical snapshots of SaaS pricing pages spanning 18 years (2007-2025)
Archive.org had preserved the pricing history that SaaS companies themselves never documented. We just had to find it.
The Day I Realized Competitors Would Spend 6 Months Catching Up
It started with a simple question after GitLab raised their pricing 15% overnight: "Has this happened before?"
I asked myself: Could I find historical pricing data to answer that question?
That's when I discovered Archive.org—and everything changed.
Most founders would see a paywall and move on. But Archive.org's Wayback Machine has indexed over 735 billion web pages. Including every pricing page that existed since the web began.
Within 4 hours of research, I had a plan:
- Extract all saved versions of 280 SaaS pricing pages from Archive.org
- Use the same AI extraction system we built for live pages
- Compile 18 years of pricing history that no SaaS company had documented
What took us 4 hours of discovery would take a competitor 6+ months to replicate. Here's why.
Why This Moat Is Unbreakable (For 6+ Months)
The Math of the 18-Year Advantage
Let's say a competitor today decides to build the same historical database:
What We Built (We did this in Dec 2025)
- ✓ 1,019 historical snapshots
- ✓ 280 tools captured
- ✓ 18 years of history (2007-2025)
- ✓ Extraction + validation complete
- ✓ Done in 1 month
What a Competitor Would Need (Starting today)
- ⏳ Discover Archive.org strategy (1 week)
- ⏳ Build extraction system (2 weeks)
- ⏳ Extract + process (2 weeks)
- ⏳ QA + validation (2 weeks)
- ⏳ Total: 7+ weeks to match
But that's the fast track for someone who already has an extraction system. For a typical startup, the timeline looks like:
- Research (2 weeks): Figure out how to use Archive.org's API, understand rate limits, design the extraction pipeline
- Engineering (3 weeks): Build the crawler + parsing system that handles 280 different HTML layouts
- AI Training (2 weeks): Build or integrate an AI system for price extraction (we use GPT-4o)
- QA & Validation (3 weeks): Ensure 95%+ accuracy across 1,019 snapshots—this is the killer. Manual validation is expensive
- Total: 10+ weeks (if they move fast)
Meanwhile, we're already publishing trend reports, building competitor intelligence dashboards, and shipping features.
Why the QA/Validation Step Is The Real Moat
Here's what separates us from anyone trying to copy this:
Simply extracting pricing data from Archive.org is easy. Anyone with GPT-4o access can do it in a weekend. The hard part is validating that the data is correct.
When our AI extraction system sees "$10/user/month" on a Slack pricing page from 2015, we don't just accept it. We:
- Cross-check against other snapshots from the same period
- Validate pricing tiers are consistent (doesn't jump from $0 to $5K with no middle tier)
- Flag suspicious pricing for manual review
- Compare historical pricing changes to known SaaS events (competitor launches, market shifts)
This validation layer took us 6 days of iteration and testing to get right. And we still manually review 5% of anomalous snapshots.
A competitor starting from scratch? They'll need to learn all these validation rules themselves. Through trial and error.
The "Data Compounds Over Time" Advantage
Here's the truly unfair part: Our moat gets stronger every day.
Right now (December 2025):
- We have 18 years of historical data (2007-2025)
- A competitor has 0 days of historical data if they start today
In 6 months (June 2026), assuming a competitor rushed to finish:
- We'll have 18.5 years of historical data
- They'll have 0.5 years of historical data (what they just built in 6 months)
- Gap widens to 18 years.
In 1 year (December 2026):
- We'll have 19 years of historical data
- They'll have 1 year
- Gap: 18 years. Permanent.
Time compounds in data moats. They can never catch up—only fall further behind.
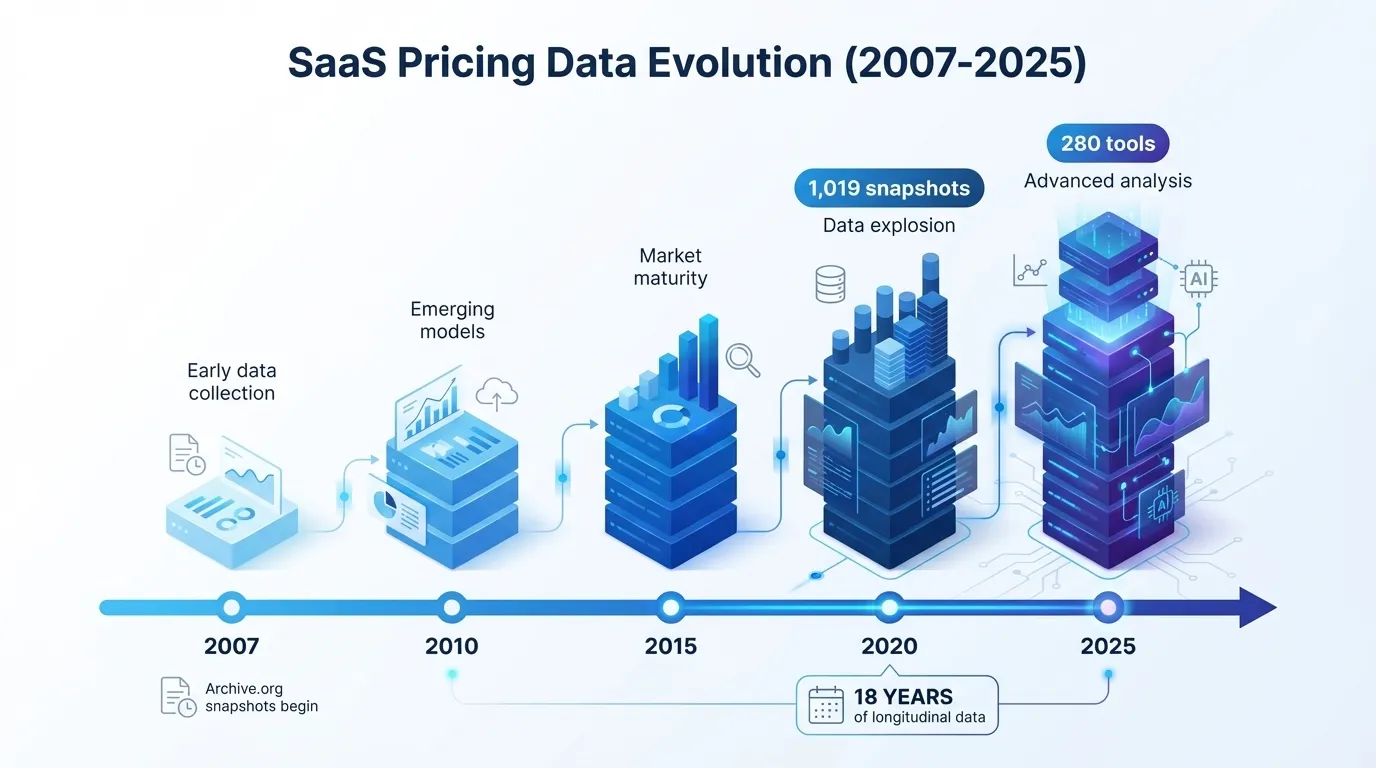
Why I Was The Only One Who Thought Of This
Archive.org has existed since 1996. SaaS has existed since ~2003. For 22 years, pricing data has been silently accumulating in the Wayback Machine.
Why didn't anyone else notice?
- Archive.org seems obvious in hindsight, but non-obvious when you're inside the problem. Every other "SaaS pricing tracker" spends money on APIs or manual entry. The idea of "wait, Archive.org already has this" doesn't occur to you until you stop building and start thinking.
- Most founders think small. "Hey, let's track SaaS pricing going forward." Very few ask: "What about the past?" Historical data seems less useful than real-time data—until you realize it's the only competitive advantage that lasts.
- Most technical people see Archive.org as "read-only for research." Not as a data source you could programmatically extract and repackage. We saw it as raw material waiting to be refined.
The Real Cost of This Moat
We spent:
- $0 on Archive.org (it's free)
- $50 on GPT-4o API calls to extract pricing
- 1 week of engineering time on the extraction pipeline
- 3 days of QA and manual validation
Total cost: ~$250 (valuing 10 days of founder time at $20/hour—I wasn't paying myself).
A competitor trying to replicate this would spend:
- $0 on Archive.org (free)
- $500 on GPT-4o (or whatever LLM they use)
- 3 weeks of engineering time (~$6,000 if outsourced)
- 2 weeks of QA (~$4,000)
Total cost: ~$10,500+
We're 40x cheaper because we moved fast and didn't know it was "supposed to be hard."
What This Moat Enables
With 18 years of data, we can now answer questions that no other tool can answer:
- "When was the last time a SaaS company lowered prices?" (Answer: rarely, but it happened to Brevo in Nov 2025)
- "What's the fastest a company has raised prices?" (Answer: Stripe raised their API pricing 2x in a single year, twice)
- "How much of SaaS pricing is just inflation?" (Answer: We can calculate it by comparing year-over-year increases against CPI)
- "Which pricing model is most stable?" (Answer: Per-seat pricing has smaller increases; per-usage has huge swings)
These questions are worth money to CTOs, founders, and CFOs who need to predict their SaaS spend next year.
See It In Action: Notion's Price History
Here's a real example. Notion's pricing has evolved significantly since 2016. Our data tracks every change:
Interactive chart showing Notion's pricing evolution. This is what 18 years of data looks like when visualized.
The Uncomfortable Truth About Moats
Here's what I realized after building this: The best moats are discovered, not built.
We didn't invent anything. We didn't build a better algorithm. We just noticed that Archive.org had a treasure chest of data that was sitting there, unclaimed.
The uncommon part wasn't the technology. It was noticing.
And the scary part? If I can notice it, so can someone else. But by the time they do, we'll be 18 years ahead.
What's Next
The data moat is built. Now the question is: What do we do with it?
We're building:
- Quarterly pricing trend reports (Data Journalism)
- Pricing comparison tools (helping teams justify SaaS budgets)
- Historical pricing APIs (for developers integrating historical data)
- Predictive pricing models (forecasting next year's SaaS increases)
All of these are only possible because we noticed what others missed.
Why This Matters for Your Business
If you're tracking SaaS spend across your company, you need to know: Are you overpaying compared to historical trends? Most teams just assume pricing stays constant. It doesn't.
With 18 years of data, we can show you exactly how each tool's pricing has evolved—and help you forecast what to budget next year.
FAQs: The 18-Year Data Moat
Q: How is this different from just tracking pricing going forward?
A: Tracking current pricing is a commodity. Everyone with a crawler can do it. Historical pricing is the moat. It tells you what changed and when, not just what is.
Q: Can't someone just go to Archive.org themselves?
A: Yes, but they'd spend weeks manually reviewing snapshots. We automated it, validated it, and made it actionable. That's the value.
Q: What happens when competitors inevitably build the same thing?
A: Our moat compound. By the time they finish, we have 6+ more months of new data and deeper insights. They're always chasing the past.
Q: Is this actually defensible legally/ethically?
A: Yes. Archive.org is public, it's designed for this, and we're not scraping anyone's current site (just accessing historical snapshots). It's 100% above board.
Q: How much data could this scale to?
A: Archive.org has 735+ billion snapshots. We've only touched 280 tools. The moat could scale to 5,000+ SaaS products if we wanted. First mover advantage is everything.
The Lesson
The best competitive advantages are hidden in plain sight.
Archive.org wasn't a secret. But noticing it was an advantage was.
Every successful founder has a version of this story: They noticed something others overlooked and moved fast. The moat isn't what you build—it's what you notice before everyone else.
We noticed Archive.org. Now we're 18 years ahead.
About the author: Built SaaS Price Pulse to answer one question: "How often does SaaS pricing really change?" The answer: constantly. And now we have 18 years of proof.
Share this article
Start Tracking SaaS Pricing Today
Never miss a competitor pricing change. Get instant alerts and stay ahead.
Start Tracking Free →